
Berikut adalah silabus “Analisis Sentimen Media Sosial Menggunakan Algoritma Naive Bayes pada Twitter dengan Python”:
Sesi 1-5: Pengantar dan Persiapan
- Sesi 1: Pengantar Analisis Sentimen
- Definisi analisis sentimen.
- Aplikasi analisis sentimen di berbagai bidang.
- Pengenalan metode dan algoritma yang digunakan.
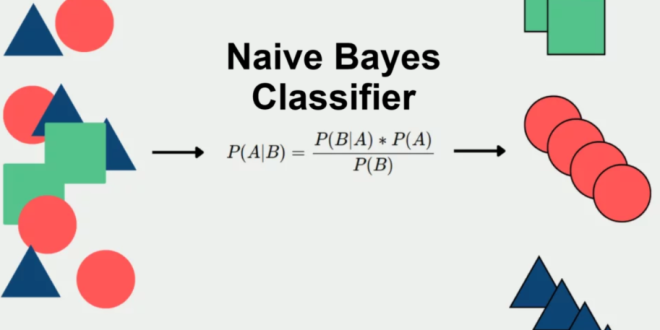
- Sesi 2: Pengenalan Naive Bayes
- Konsep dasar Naive Bayes.
- Teorema Bayes dan asumsi independensi.
- Kelebihan dan kekurangan Naive Bayes dalam analisis sentimen.
- Sesi 3: Pengantar Python untuk Pemrosesan Bahasa Alami
- Pengenalan Python dan library terkait (numpy, pandas, scikit-learn).
- Instalasi dan setup lingkungan kerja.
- Sesi 4: Pengenalan Pemrosesan Bahasa Alami (NLP)
- Dasar-dasar NLP.
- Pengenalan library NLTK dan spaCy.
- Operasi dasar dalam NLP: tokenisasi, stemming, lemmatization.
- Sesi 5: Pengantar Twitter API
- Cara kerja Twitter API.
- Mendaftarkan aplikasi dan mendapatkan kunci API.
- Mengambil data dari Twitter menggunakan Tweepy.
Sesi 6-10: Pengumpulan dan Pemrosesan Data
- Sesi 6: Mengambil Data dari Twitter
- Menggunakan Tweepy untuk mengambil tweet.
- Menyimpan data dalam format CSV.
- Membuat filter pencarian berdasarkan kata kunci.
- Sesi 7: Eksplorasi Data
- Eksplorasi data awal (jumlah tweet, pengguna, dan tanggal).
- Analisis data teks sederhana.
- Mengatasi masalah missing data dan duplikasi.
- Sesi 8: Preprocessing Data Teks
- Pembersihan teks (hapus URL, emoji, dan karakter spesial).
- Stop words removal, stemming, dan lemmatization.
- Representasi teks menggunakan bag-of-words dan TF-IDF.
- Sesi 9: Labeling Data Sentimen
- Metode labeling: manual dan otomatis.
- Pengenalan dataset sentimen (misalnya, IMDb atau dataset sentimen lainnya).
- Menetapkan label positif, negatif, atau netral pada tweet.
- Sesi 10: Splitting Data
- Membagi data menjadi training dan testing set.
- Teknik stratified sampling.
- Pengenalan konsep cross-validation.
Sesi 11-15: Pembangunan Model
- Sesi 11: Pengenalan Scikit-Learn
- Pengenalan Scikit-Learn untuk machine learning.
- Struktur dasar pipeline di Scikit-Learn.
- Menggunakan fitur extraction untuk teks.
- Sesi 12: Membangun Model Naive Bayes
- Implementasi Multinomial Naive Bayes untuk data teks.
- Memahami parameter dan hyperparameter dalam Naive Bayes.
- Latih model pada data training.
- Sesi 13: Evaluasi Model
- Menghitung akurasi, presisi, recall, dan F1-score.
- Membuat confusion matrix.
- Visualisasi hasil evaluasi.
- Sesi 14: Hyperparameter Tuning
- Teknik hyperparameter tuning (Grid Search, Random Search).
- Menerapkan Grid Search untuk model Naive Bayes.
- Evaluasi performa model setelah tuning.
- Sesi 15: Validasi Model dengan Cross-Validation
- Implementasi k-fold cross-validation.
- Analisis hasil cross-validation.
- Perbandingan performa model dengan berbagai parameter.
Sesi 16-20: Penerapan dan Integrasi
- Sesi 16: Memprediksi Sentimen pada Data Baru
- Implementasi model pada data baru.
- Analisis prediksi dan interpretasi hasil.
- Menyimpan hasil prediksi ke dalam file.
- Sesi 17: Integrasi dengan API untuk Analisis Real-Time
- Membuat stream listener dengan Tweepy.
- Mengintegrasikan model untuk prediksi real-time.
- Menampilkan hasil prediksi secara real-time.
- Sesi 18: Visualisasi Data Sentimen
- Visualisasi hasil prediksi menggunakan matplotlib dan seaborn.
- Membuat grafik pie, bar, dan word cloud.
- Menginterpretasikan hasil visualisasi.
- Sesi 19: Deployment Model dengan Flask
- Pengenalan Flask untuk web deployment.
- Membangun API sederhana untuk prediksi sentimen.
- Mengintegrasikan model Naive Bayes dengan Flask.
- Sesi 20: Pengujian API Sentimen
- Pengujian API menggunakan Postman.
- Debugging dan penanganan error.
- Membuat dokumentasi sederhana untuk API.
Sesi 21-25: Optimasi dan Peningkatan Model
- Sesi 21: Optimasi Model dengan Teknik NLP Lanjutan
- Penggunaan n-grams untuk model.
- Menggunakan word embeddings (Word2Vec, GloVe).
- Analisis perbandingan hasil dengan teknik dasar.
- Sesi 22: Penanganan Data Imbalance
- Teknik oversampling dan undersampling.
- Penggunaan SMOTE untuk penyeimbangan data.
- Evaluasi performa model setelah penyeimbangan.
- Sesi 23: Penggunaan Algoritma Tambahan
- Implementasi algoritma lain (Logistic Regression, SVM).
- Perbandingan performa dengan Naive Bayes.
- Menggabungkan beberapa model (ensemble methods).
- Sesi 24: Peningkatan Performa dengan Feature Engineering
- Menambahkan fitur tambahan (misalnya, panjang teks, jumlah kata).
- Implementasi feature selection.
- Analisis hasil setelah penambahan fitur.
- Sesi 25: Integrasi dengan Dashboard untuk Visualisasi
- Membangun dashboard menggunakan Dash atau Streamlit.
- Menampilkan hasil analisis sentimen secara interaktif.
- Pengaturan filter dan grafik dinamis pada dashboard.
Sesi 26-30: Studi Kasus dan Penutup
- Sesi 26: Studi Kasus I – Analisis Sentimen pada Topik Tertentu
- Pemilihan topik (misalnya, produk, politik, atau acara).
- Implementasi model pada dataset khusus.
- Analisis hasil dan interpretasi.
- Sesi 27: Studi Kasus II – Analisis Sentimen pada Event
- Mengambil data tweet terkait event tertentu.
- Implementasi model dan analisis sentimen.
- Visualisasi perubahan sentimen selama event.
- Sesi 28: Penulisan Laporan Hasil Analisis
- Struktur laporan: pendahuluan, metode, hasil, dan diskusi.
- Menyusun hasil analisis menjadi laporan lengkap.
- Membuat presentasi hasil analisis.
- Sesi 29: Presentasi Hasil Analisis
- Teknik presentasi yang efektif.
- Menyampaikan hasil analisis dan interpretasi.
- Diskusi dan tanggapan dari audiens.
- Sesi 30: Evaluasi dan Penutup
- Review keseluruhan proses.
- Diskusi tentang tantangan dan solusi.
- Evaluasi akhir dan sertifikasi (jika ada).
Semoga silabus ini dapat membantu dalam pengembangan proyek Anda!





